The human baby is endowed with probabilistic reasoning skills. The child's brain makes predictions about the outside world and seems to have a powerful algorithm for learning statistical regularities (Stanislas Dehaene, Collège de France, 2013).
It is known that children can extract words from a monotone speech stream using only the transition probabilities between syllables, which means that they can determine the frequency with which one syllable is followed by another and use this information to segment continuous speech. In other words, thanks to this statistical learning capacity, toddlers spot events that have a high probability of following each other. As the team has demonstrated in several recent studies, this simple mechanism is part of the human infant's toolbox for discovering regularities in speech from birth. However, the question of whether statistical learning is a mechanism dedicated exclusively to the acquisition of language is still being debated, and recent work shows that this capacity exists for other types of learning (non-vocal sounds such as tones, visual shapes, actions), as well as in different species.
DEMONSTRATING THE UNIVERSALITY OF STATISTICAL LEARNING MECHANISMS
In the present study, the team exploited the two dimensions conveyed by speech, namely speaker identity and phonemes, in order to assess: i) whether newborns can calculate Transitional Probabilities (TPs) on one dimension while ignoring irrelevant variations on the other, and ii) whether the linguistic dimension (phonemes) has an advantage over the vocal dimension (speaker identity). Two high-density (128 electrodes) electroencephalography (EEG) experiments were conducted while sleeping neonates were exposed to artificial speech streams created from six syllables pronounced by six different voices, i.e. a total of 36 possible tokens (6 syllables × 6 voices) : either the sequence had a statistical structure based on phonetic content, while the voices varied randomly (experiment 1), or the structure was based on voices with random phonetic content (experiment 2). After familiarisation, the newborns heard isolated duplets adhering or not to the structure with which they had been familiarised. The results reveal neural training in the frequency of the regularity of the presentation of linguistic duplets showing, as in previous studies, that newborns detect the probabilities of frequent transitions between syllables but also, in experiment 2, in the frequency of voice duplets. In addition, a surprise response was recorded for incorrect duplets compared with correct duplets in both experiments. These observations underline the universality of statistical learning mechanisms across many dimensions and cognitive domains. Nevertheless, only linguistic duplets give rise to a specific component linked, in adults, to lexical associations, suggesting an early neural signature of access to the lexicon which, at this age, is probably limited to a dictionary of linguistically relevant forms.
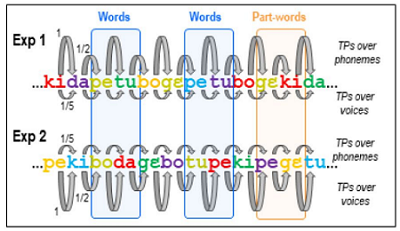
Diagram of the structured sequence in the two experiments. Flo et al, eLife 2025
Taken together, these results suggest that i) from birth, multiple input regularities can be processed in parallel by human newborns and feed different higher-order networks, ii) statistical learning may play a more important role than previously thought in early language acquisition, iii) this learning is robust and not limited to linguistic features.
Contacts : Ghislaine Dehaene-Lambertz (gdehaene@gmail.com) ; Marie Palu (marie.palu@cea.fr)