Le bébé humain est doté de compétences pour le raisonnement probabiliste. Le cerveau de l'enfant émet des prédictions sur le monde extérieur et semble disposer d'un puissant algorithme d'apprentissage de régularités statistiques (Stanislas Dehaene, Collège de France, 2013).
Il est connu que les enfants peuvent extraire des mots d'un flux de parole monotone en utilisant uniquement les probabilités de transition entre les syllabes, ce qui signifie qu'ils peuvent déterminer la fréquence à laquelle une syllabe est suivie d'une autre et utiliser cette information pour segmenter un discours continu. En d'autres termes, grâce à cette capacité d'apprentissage statistique, les tout-petits repèrent les évènements qui ont une haute probabilité de se suivre. Comme l'équipe l'a démontré dans plusieurs études récentes, ce mécanisme simple fait partie de la boîte à outils du nourrisson humain pour découvrir des régularités dans la parole depuis la naissance. Cependant, la question de savoir si l'apprentissage statistique est un mécanisme dédié exclusivement à l'acquisition du langage est toujours débattue et des travaux récents montrent que cette capacité existe pour d'autres apprentissages (sons non vocaux comme les tonalités, formes visuelles, actions), ainsi que dans différentes espèces.
MISE EN ÉVIDENCE DE L'UNIVERSALITÉ DES MÉCANISMES D'APPRENTISSAGE STATISTIQUE
Dans la présente étude, l'équipe a exploité les deux dimensions véhiculées par la parole, à savoir l'identité du locuteur et les phonèmes, dans le but d'évaluer : i) si les nouveau-nés peuvent calculer les probabilités de transitions (Transitional Probabilities, TP) sur une dimension tout en ignorant les variations non pertinentes sur l'autre et ii) si la dimension linguistique (phonèmes) bénéficie d'un avantage sur la dimension vocale (identité du locuteur). Deux expériences d'électroencéphalographie (EEG) à haute densité (128 électrodes) ont été menées pendant que des nouveau-nés endormis étaient exposés à des flux de parole artificiels créés à partir de six syllabes prononcées par six voix différentes, soit un total de 36 jetons possibles (6 syllabes × 6 voix) : soit la séquence possédait une structure statistique basée sur le contenu phonétique, tandis que les voix variaient aléatoirement (expérience 1), soit la structure était basée sur des voix au contenu phonétique aléatoire (expérience 2). Après familiarisation, les nouveau-nés ont entendu des duplets isolés adhérant ou non à la structure avec laquelle ils avaient été familiarisés. Les résultats révèlent un entraînement neuronal à la fréquence de la régularité de la présentation des duplets linguistiques montrant, comme dans les études précédentes, que les nouveau-nés détectent les probabilités de transitions fréquentes entre syllabes mais aussi, dans l'expérience 2, à la fréquence des duplets de voix. De plus, une réponse de surprise est enregistrée pour les duplets incorrects par rapport aux duplets corrects, dans les deux expériences. Ces observations soulignent l'universalité des mécanismes d'apprentissage statistique à travers de nombreuses dimensions et domaines cognitifs. Néanmoins, seuls les duplets linguistiques donnent lieu à un composant spécifique lié, chez l'adulte, aux associations lexicales suggérant une signature neuronale précoce d'un accès au lexique qui, à cet âge, se limite probablement à un dictionnaire de formes linguistiquement pertinentes.
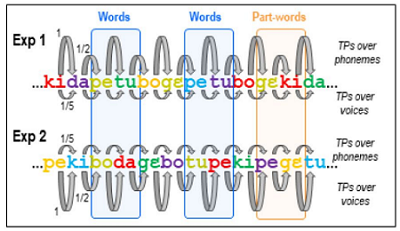
Schéma de la séquence structurée dans les deux expériences. Flo et al., eLife 2025
L'ensemble de ces résultats suggère que i) dès la naissance, de multiples régularités d'entrée peuvent être traitées en parallèle par les nouveau-nés humains et alimenter différents réseaux d'ordre supérieur, ii) l'apprentissage statistique pourrait jouer un rôle plus important qu'on ne le pensait dans l'acquisition précoce du langage, iii) cet apprentissage est robuste et ne se limite pas aux caractéristiques linguistiques.
Texte dérivé de celui publié dans la dernière lettre d'information du NeuroKids Lab (janvier 2025) ; https://moncerveaualecole.com/
Contacts : Ghislaine Dehaene-Lambertz (gdehaene@gmail.com) ; Marie Palu (marie.palu@cea.fr)